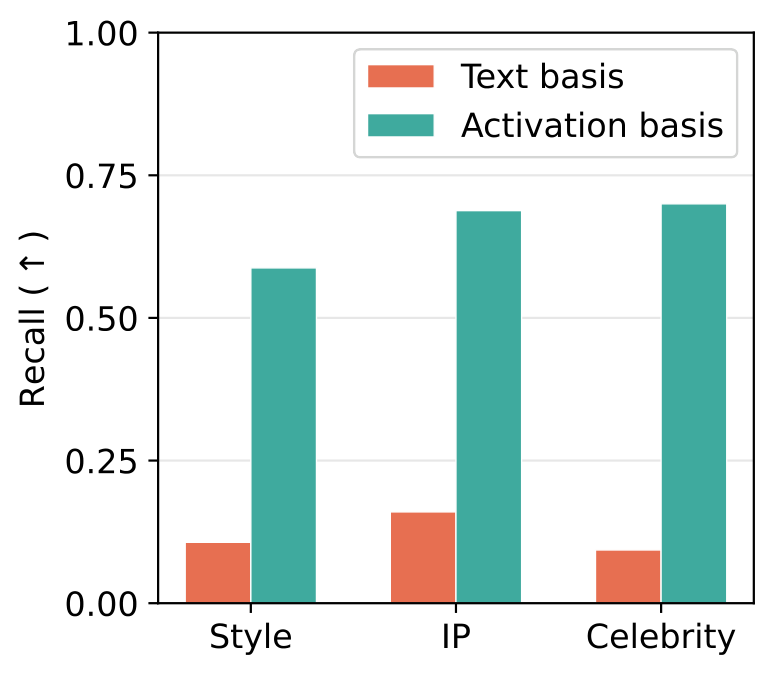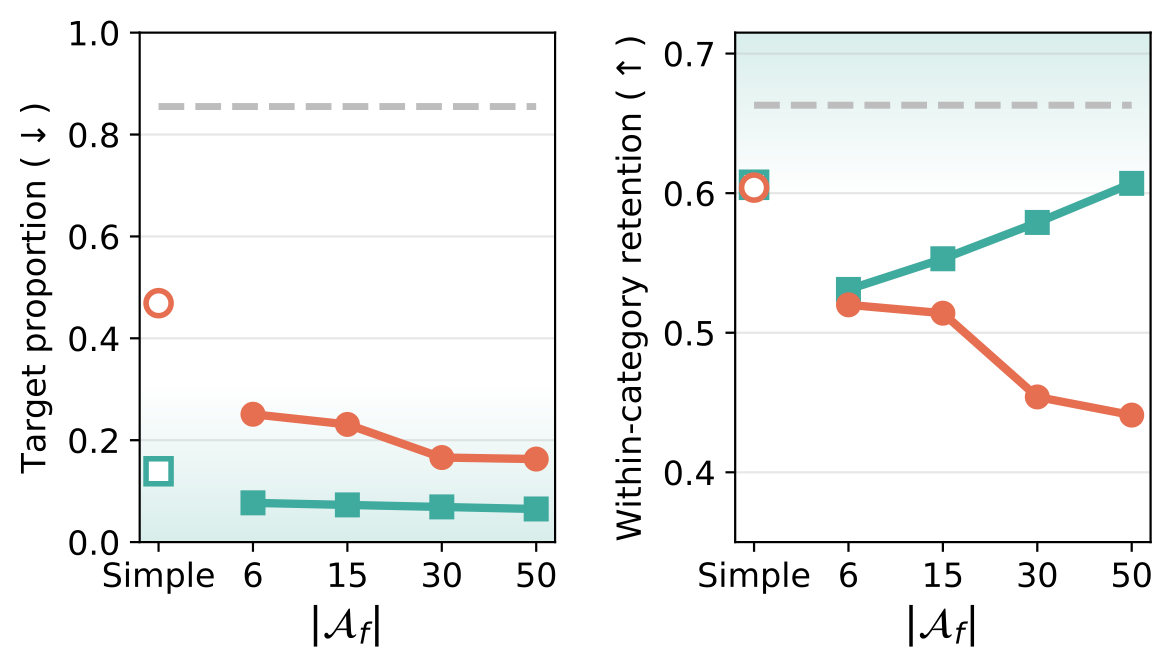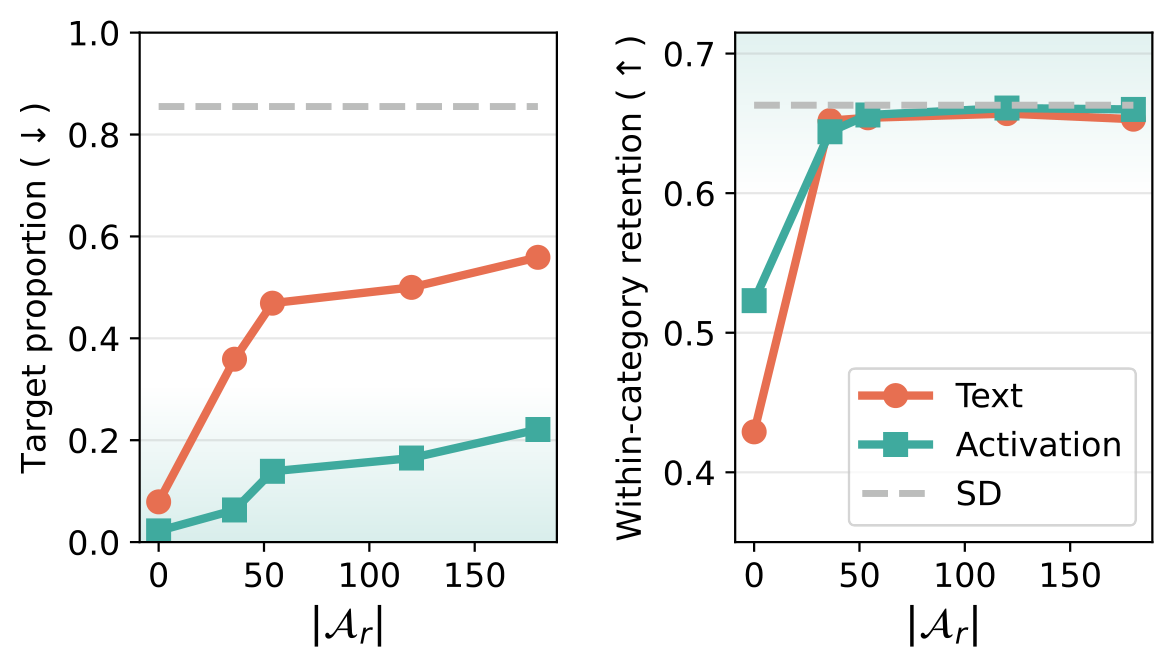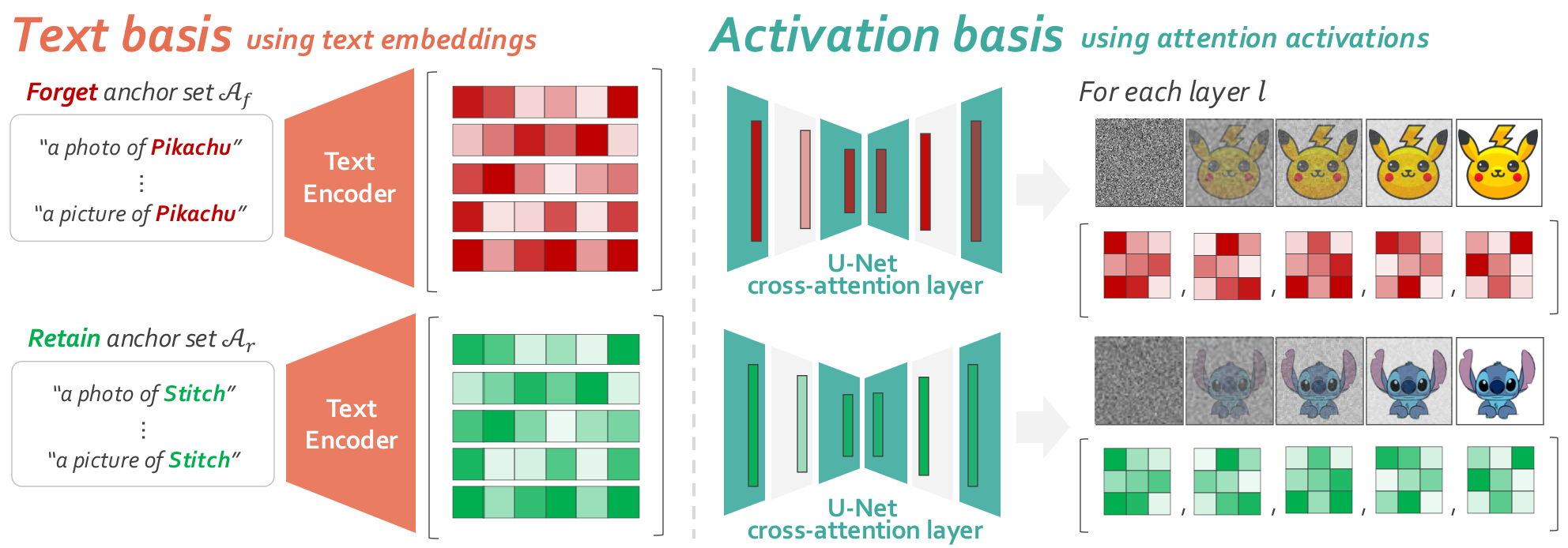
We build a basis from a small set of short anchor prompts, either from text-encoder embeddings or from cross-attention activations, then train a binary classifier in that basis. We measure recall on a held-out set of natural prompts that describe the same concept in longer, more varied form than the anchors.
A text-space basis catches only a small fraction. A cross-attention activation basis recovers 5 to 7 times more across artistic style, intellectual property, and celebrity categories.
This is the core motivation for PURE: erase the target where the model actually represents it.